
Comme nous l’avons vu dans l’article précédent part 1, le traitement du langage naturel offre des capacités intéressantes qui changent de nombreuses industries aujourd’hui. Comment l’ordinateur arrive-t-il à avoir une aussi grande intelligence artificielle ?
cadre de traitement du langage naturel
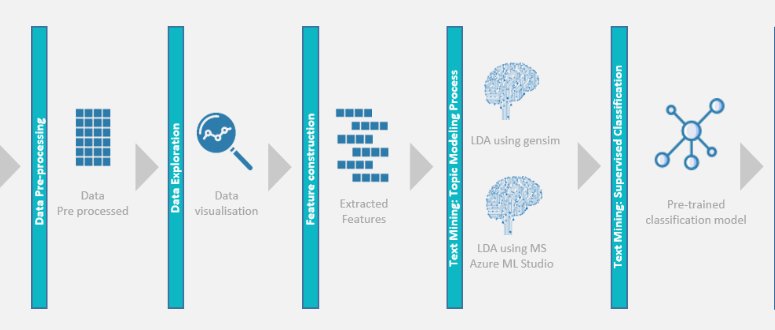
Nous allons construire étape par étape un cadre de traitement du langage naturel, et à la fin de ce « tutoriel », vous serez en mesure de construire votre propre modèle de traitement de langage naturel.
Tout d’abord, examinons ce texte. C’est une citation de Bill Gates

Ce serait génial si mon ordinateur pouvait lire cette citation, et surtout « la comprendre », n’est-ce pas ? Pour y arriver, nous devons suivre quelques étapes.
Le prétraitement des données
Le prétraitement des données est considéré comme la partie la plus ennuyeuse du travail parce qu’il est techniquement peu attrayant et relativement laborieux. Il y a un proverbe célèbre parmi les scientifiques de données qui dit, « Ordures dedans, ordures dehors ». Cela signifie que si vous alimentez votre modèle d’apprentissage automatiquement avec des données sales, il va le rejeter.
Autrement dit, cela vous donnera des résultats insignifiants. C’est pourquoi cette partie du travail doit être effectuée avec rigueur.
Habituellement, lorsqu’il s’agit de données structurées, le prétraitement des données consiste à supprimer les données en double, les valeurs nulles et les erreurs.
En ce qui concerne les données textuelles, il existe de nombreuses techniques communes de prétraitement des données, également appelées techniques de nettoyage des textes.
Afin d’appliquer les techniques de prétraitement, nous allons utiliser une bibliothèque Python très puissante : NLTK : Natural Language Toolkit. NLTK fournit une suite de bibliothèques de traitement de texte pour la classification, la tokenisation, le bourrage, le marquage, etc. Accrochez-vous, nous sommes sur le point de voir toutes ces fonctionnalités ensemble en quelques minutes.
Segmentation des peines :
Essentiellement, il s’agit de scinder notre texte en phrases distinctes. Dans notre cas, nous nous retrouverons avec ceci :
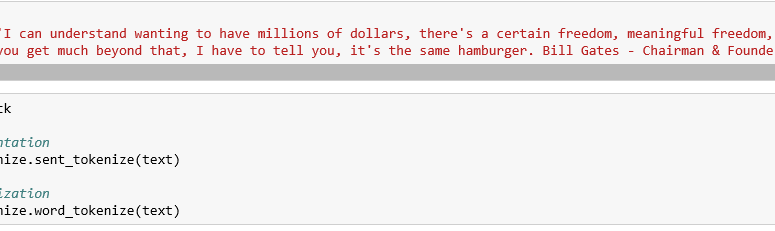
- « I can understand wanting to have millions of dollars, there’s a certain freedom, meaningful freedom, that comes with that.”
- “But once you get much beyond that, I have to tell you, it’s the same hamburger.”
- “Bill Gates – Chairman & Founder of Microsoft”
Dans ce cas, on peut supposer que chaque phrase représente une idée distincte. Par conséquent, il sera beaucoup plus facile de développer un algorithme qui comprend une seule phrase que l’ensemble du paragraphe.
Tokenization
Maintenant nous divisons notre texte en phrases et le décomposons en mots
Par exemple, commençons par la première phrase de notre citation :
« I can understand wanting to have millions of dollars, there’s a certain freedom, meaningful freedom, that comes with that.”
Après application de la tokenization, il finira comme suit :
« I”, “can”, “understand”, “wanting”, “to”, “have”, “millions”, “of”, “dollars”, “,”, “there’s”, ”a”, “certain”, “freedom”, “,”, “meaningful”, “freedom”, “,”, “that”, “comes”, “with”, “that”, “.”
Suppression de texte :
Faire des textes plus courts : C’est une sorte de point de contrôle de normalisation pour éviter le nombre de caractères que nous traitons.
Élargir les contractions : L’anglais informel est plein de contractions qui devraient être remplacées, toujours dans une tentative de normaliser notre texte autant que nous le pouvons.
Par exemple, dans notre citation, « there’s» sera remplacé par « there is ».

Supprimer les ponctuations : Les signes de ponctuation représentent des caractères indésirables, alors enlevons-les.

Corriger les fautes d’orthographe : L’idée est simple ; nous allons utiliser un gros corpus comme référence pour corriger l’orthographe des mots dans notre texte.
Supprimer les mots à répétition : Les mots à répétition sont des mots surutilisés qui ne contiennent aucune information importante supplémentaire pour le message que chaque texte tient. La plupart des mots d’arrêt courants sont des déterminants (e.g. the, a, an), des prépositions (e.g. above, across, before) et certains adjectifs (e.g. good, nice). On les supprime !

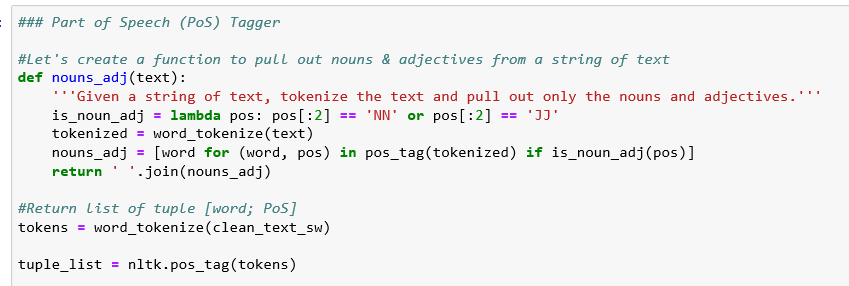
Partie du filtrage de la parole : Le but est d’identifier chaque catégorie lexicale de mot en lui donnant un tag : Verbe, Adjectif, Nom, Adverbe, Pronom, Préposition…
Dans notre cas, « I can understand wanting to have millions of dollars” devient “I can understand [want] to have [million] of [dollar]”

Lemmatisation du texte : Dans la plupart des langues, les mots peuvent apparaître sous différentes formes. Il serait intéressant de remplacer chaque mot par sa forme de base, afin que notre ordinateur puisse comprendre que des phrases différentes puissent parler du même concept. Alors Llamatize notre citation !
Dans notre cas, “I can understand wanting to have millions of dollars” devient“I can understand [want] to have [million] of [dollar]”

Reconnaissance de l’entité nommée : il s’agit d’un processus où un algorithme prend une chaîne de texte (phrase ou paragraphe) comme entrée et identifie les noms pertinents (personnes, lieux, organisations, etc.) qui sont mentionnés dans cette chaîne.


Ecrit par Sofiene AZABOU.